


Уточненные законы Зипфа легли в основу алгоритмов автоматического распознавания текста, реализованных в специальных программах-экстракторах. С их помощью можно выполнить семантический анализ текстов и извлечь ключевые слова и выражения, необходимые для квалифицированного поиска.
Есть два основных вида поиска в электронных (и не только) каталогах библиотек. Первый — детерминированный — используется, когда известен хотя бы один из основных атрибутов определенной книги (фамилия и инициалы автора, название, индекс ISBN). Его результат показывает только наличие данной книги в конкретной библиотеке.
Другой вид — недетерминированный, или вероятностный, поиск — используют, чтобы подобрать литературу по какому-либо конкретному вопросу. Он требует работы с тематическим каталогом и может быть основан на одном из классификационных индексов (УДК или ББК). Его называют вероятностным, так как заранее неизвестно, будут ли найдены ссылки на какие-либо источники. С этим видом поиска сталкиваются не только специалисты, но и студенты, реже — школьники.
До 1990-х гг. это был, по существу, единственный реальный способ поиска нужной литературы. С появлением же компьютеров и текстовых баз данных открылась возможность автоматизированного поиска литературы по заданной тематике, основанного на применении поискового выражения, составленного на основе так называемых ключевых слов.
Сравнительно редкое применение классификационных индексов в процессе недетерминированного поиска можно объяснить трудностями работы с такими классификаторами, связанными с отсутствием четких тематических градаций, а также отсутствием необходимых профессиональных библиографических знаний у большинства пользователей тематических каталогов. Кроме того, очень многие работы лежат на стыке нескольких научных областей или направлений, что затрудняет их поиск и классификацию.
Поэтому более чем в 90% случаев используется тематический поиск на основе ключевых слов и выражений. Чтобы он был успешным, требуется предварительно выполнить 2 условия. Первое — для всех литературных источников, хранимых в библиотеке, предварительно выбрать наиболее релевантные (в наибольшей степени соответствующие их содержанию) ключевые слова и выражения. Второе — используемые для поиска ключевые слова и выражения должны полностью соответствовать тематическому направлению. Важно определить, сколько ключевых слов целесообразно извлекать из литературного источника, какое их число следует использовать в поисковом выражении, каким образом оно будет составлено.
Лучше извлечь ключевые слова и выражения может узкий специалист, хорошо знакомый с тематикой работы. Но ручной труд квалифицированных специалистов крайне дорог и малопроизводителен. Целесообразно автоматизировать процедуру извлечения ключевых слов. Кроме того, накопилось огромное количество книг, журналов и сборников, которые еще предстоит подвергнуть семантическому анализу с целью извлечения ключевых слов и выражений.
Автоматизация такого труда возможна на основе законов, установленных в середине прошлого века известным математиком Джорджем Зипфом и развитых другим не менее известным математиком Бенуа Мандельбротом.
Дж. Зипф (G. K. Zipf) показал, что все созданные человеком тексты подчиняются некоторым общим закономерностям. Три таких закона он сформулировал в 1946–49 гг. Так, в любом тексте можно подсчитать, какие слова в нем сколько раз встречаются. Количество повторов слова в тексте можно назвать частотой этого слова. Чаще всего встречающемуся слову можно приписать ранг 1, следующему по частоте — ранг 2 и т. д. Если несколько разных слов имеют одинаковые частоты, то учитывается только одно из них. Если разделить частоту повторения слова f на общее количество значащих слов в тексте S, то получим относительную частоту или вероятность встречи этого слова в тексте.
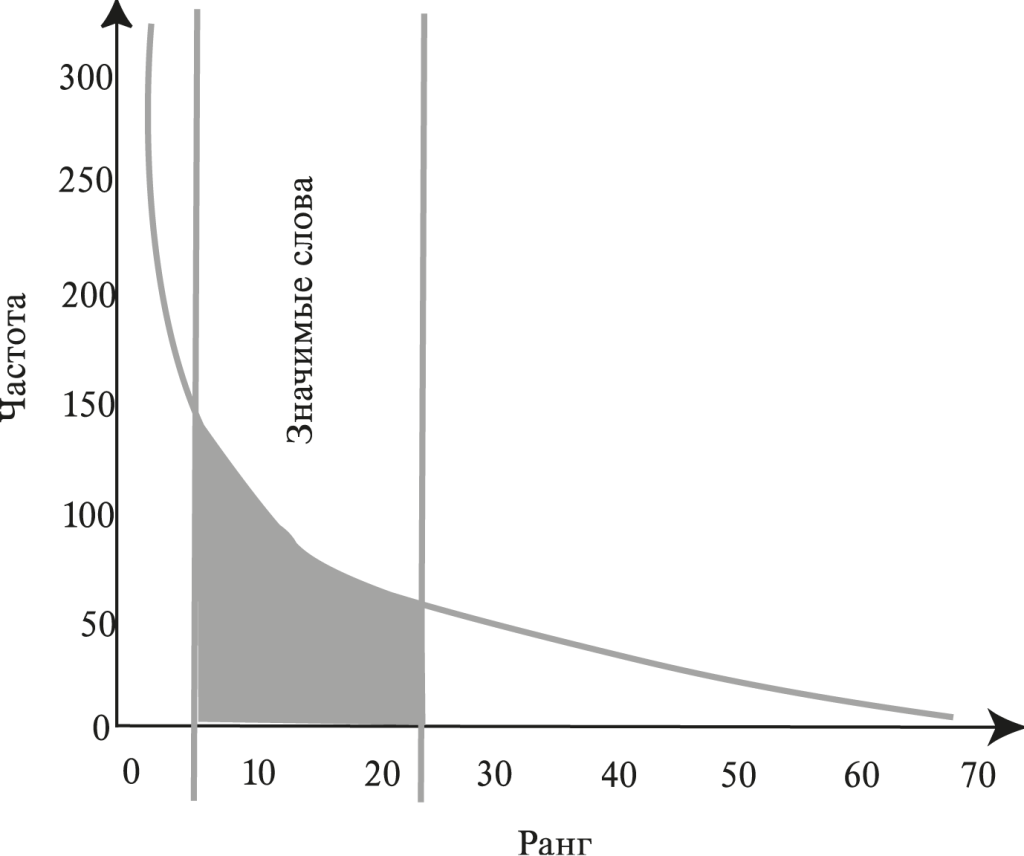
Первый закон Зипфа гласит, что произведение частоты или вероятности встречи слова в тексте на его ранг — приблизительно постоянно для любых текстов определенного языка. На рис. 1 представлена связь частоты слова в тексте f и его ранга R; кривая близка к гиперболе вида f = C / R, где C — некоторая константа. Из закона следует, что если самое распространенное слово встречается в тексте, например, 100 раз, то следующее по частоте слово вряд ли встретится 99 раз. Частота вхождения второго по популярности слова с высокой долей вероятности окажется на уровне 50. Значение константы в разных языках различно, но внутри одной языковой группы остается неизменно для любого текста.
Законы Зипфа весьма универсальны. Они применимы не только к текстам, но и ко многим другим статистическим закономерностям, в частности, законам Зипфа соответствуют характеристики популярности узлов в сети интернет.
Полученные Зипфом результаты могут успешно использоваться на практике для выделения терминов (ключевых слов и выражений) в тексте и их последующего извлечения. Отметим, что все значащие слова для данного текста размещаются в области средних значений ранга и частоты (выделенная область на рис. 1). Действительно, самые часто встречающиеся слова, ранг которых обычно изменяется от 1 до 4—5, относятся к разряду вспомогательных, а самые редкие — также не имеют решающего смыслового значения для данного текста. От того, как будет задан диапазон значений ранга для извлечения ключевых слов, зависит многое. Если сделать его слишком широким — нужные термины потонут в море второстепенных, малозначимых для текста слов. Установив же чрезмерно узкий диапазон, мы рискуем потерять некоторые смысловые термины.
В свою очередь, каждый отдельно взятый текстовый документ можно представить как часть определенной совокупности документов, которая может быть реализована в виде сборника статей, параграфов или глав книг, фрагмента текстовой базы данных. Базу или ее часть, включающую документы близкой тематики или направления, можно представить в виде одного, очень большого или составного документа, к которому также применимы законы Зипфа. Использование понятия «составной документ» позволяет повысить качество выборки ключевых слов (или их рейтинг) путем введения нового понятия «инверсная частота термина», которая характеризует вес или значимость этого термина. Этот параметр позволяет снизить опасность попадания малозначащих терминов в состав выборки. Инверсная частота i определяется как логарифм по основанию два отношения общего количества документов n к числу документов, содержащих данный термин m (под термином может пониматься не только отдельное слово, но и единое по смыслу словосочетание), т. е.
i = log2(n/m).(1)
С учетом инверсной частоты вес или значимость термина z в каждом отдельном документе определится выражением
Z = f х i / S,(2)
где S — количество значащих слов в определенном документе. Кстати, вес или значимость одного и того же термина в различных документах обычно существенно отличается друг от друга.
Роль инверсной частоты в приведенной формуле состоит в том, чтобы уменьшить вес слов и устойчивых словосочетаний, которые выполняют вспомогательные функции в документе, обеспечивая стиль и определенный характер повествования. Для случайных слов и сочетаний мала частота повторения терминов f, а для не имеющих смыслового значения слов (предлогов, союзов и пр.) и вспомогательных понятий стремится к нулю инверсная частота i. Таким образом, вес или значимость термина z позволяет выделить именно ключевые слова и сочетания. Этот же параметр позволяет также ранжировать значащие слова, т. е. выстроить их последовательность в порядке снижения значимости.
Законы Зипфа используются при создании ссылочной базы данных на поисковых серверах, причем весовые коэффициенты основаны не только на весе каждого термина, но могут учитывать и то, какой частью речи является термин, а также его местоположение внутри документа, морфологические особенности и пр. Они же используются для оценки релевантности найденного в процессе поиска документа, величина которой изменяется от 0 до 1. Релевантность оценивается на основе того, какое количество слов из представленных в поисковом выражении содержится в найденном документе, а также веса каждого из таких слов, представленных в документе.
На основе ряда практических исследований законы Зипфа позднее уточнил известный математик Бенуа Мандельброт (Benoit B. Mandelbrot). В настоящее время эти законы легли в основу алгоритмов автоматического распознавания текста, реализованных в специальных программах-экстракторах, на основе которых и может быть выполнен семантический анализ текстов и извлечены ключевые слова и выражения. Программ таких не слишком много, хотя потребность в них постепенно растет.
Возможность извлечения ключевых слов из текстовых материалов декларируется в наиболее распространенном у нас текстовом редакторе MS Word различных версий. В меню «Сервис» предусмотрена команда «Автореферат», позволяющая выделить из документа несколько предложений. Если затем воспользоваться командой «Файл/Свойства», то в появившемся диалоговом окне в одной из 5 вкладок можно увидеть строку, где будет выведено 5 ключевых слов. Но проведенные нами исследования показали, что данная опция в пакете работает неудовлетворительно: из извлеченных из текста 5 слов только 1–2 соответствуют тематическому направлению, причем обычно ни одно из них не имеет высокой значимости.
Одной из лучших программ-экстракторов, по нашему мнению, является современная версия TextAnalyst 2.01. Она позволяет сделать:
• анализ содержания текста с автоматическим формированием семантической сети с гиперссылками — получения смыслового портрета текста в терминах основных понятий и их смысловых связей;
• анализ содержания текста с автоматическим формированием тематического древа с гиперссылками — выявления семантической структуры текста в виде иерархии тем и подтем;
• автоматическое реферирование текста — формирования его смыслового портрета в терминах наиболее информативных фраз;
• ранжирование информации о семантике текста по «степени значимости» с возможностью варьирования степени детальности ее исследования;
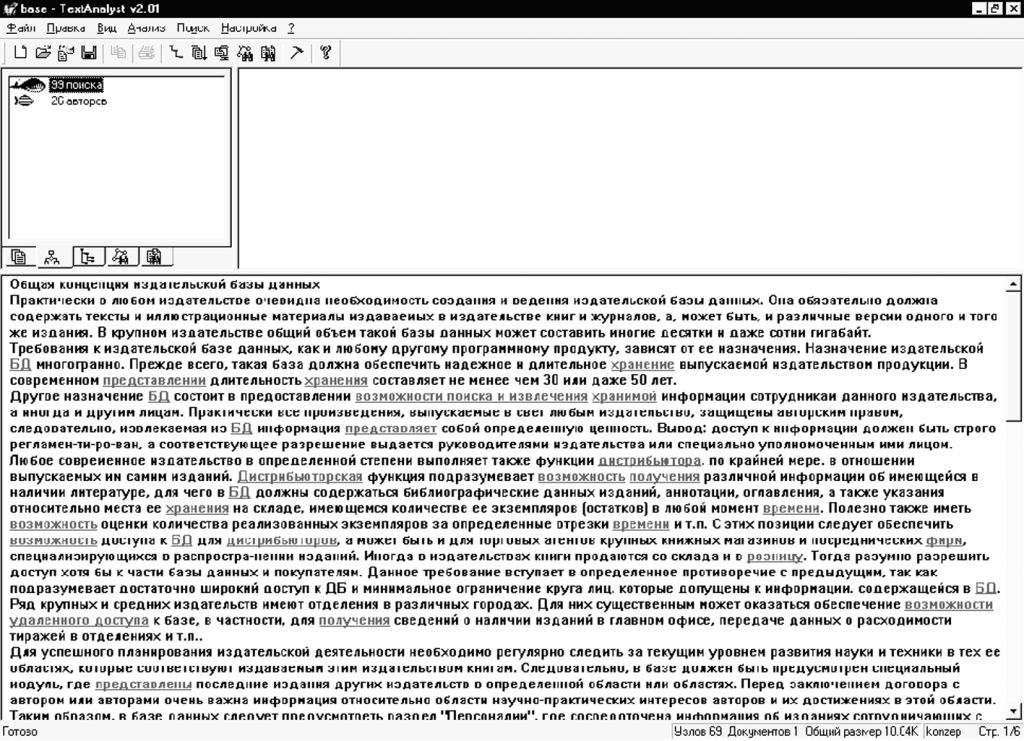
Результаты работы программы TextAnalyst 2.01. представлены на рис. 2 Анализу была подвергнута статья «Общая концепция издательской базы данных». Интерфейс TextAnalyst 2.01 построен в виде трех взаимосвязанных окон:
• «окно 1» — окно значимых элементов текста, располагается в левом верхнем углу экрана;
• «окно 2» — окно отсылок к предложениям текстов, располагается в правом верхнем углу экрана;
• «окно 3» — окно анализируемых текстов, располагается в нижней части экрана.
Сеть понятий
Если перейти к закладке «Семантическая сеть» в окне 1 (третья кнопка слева), то в окне 1 будет представлена (в виде обычного дерева) сеть основных понятий проанализированных текстов.
Изучив предложенный материал, TextAnalyst формирует сеть основных (наиболее значимых) понятий, содержащихся в представленном ему тексте. Она служит смысловым представлением текста и основой для всех видов дальнейшего анализа. Сеть понятий — это множество терминов из текстов — слов и словосочетаний, связанных между собой по смыслу. В нее включены не все термины текста, а лишь наиболее значимые, несущие основную смысловую нагрузку. Аналогичным образом представлены и смысловые связи между понятиями текстов — отражаются лишь наиболее явно выраженные из них. Поэтому, с одной стороны сеть достаточно полно описывает смысл анализируемого текста, а с другой — позволяет отбросить несущественную информацию и представить содержание в сжатом виде, так называемым «смысловым портретом». При этом каждое понятие, повторявшееся в различных местах документа, оказывается представленным в единственном узле сети. В нем также собирается разбросанная информация, касающаяся этого понятия, — формируется список предложений, в которых оно употреблялось.
Различные формы слов, конечно же, приводятся к общей грамматической форме для отображения в один элемент сети. Аналогичным образом собирается информация по смысловым связям каждого понятия — в виде списка всех связанных с ним в тексте понятий, дополненного предложениями, в которых отражаются данные связи. Таким образом, можно сразу увидеть всю информацию по каждому понятию — тематике текста, буквально бросив единственный взгляд на набор его связей в сети. В результате, передвигаясь по смысловым связям от понятия к понятию, можно находить и предметно исследовать лишь наиболее важные и интересующие исследователя места документа, не затруднясь просмотром всей промежуточной информации. Это показано на рис. 3 (интерфейс программы TextAnalyst 2.01 с загруженным текстовым документом и результатами анализа семантической структуры этого документа).
Каждый элемент сети, т. е. определенное понятие, характеризуется некоторой численной величиной — так называемым «смысловым весом». Связи между парами понятий, в свою очередь, также характеризуются весами. Эти оценки позволят сравнить относительный вклад различных понятий и их связей в семантику текста, выявить наиболее подробно проработанную в тексте тематику и вторичные темы, задать способ сортировки информации, и наконец, позволят взглянуть на весь текстовый материал по пластам — смысловым срезам различной глубины — от поверхностного знакомства с содержанием до глубокого проникновения в его мельчайшие детали и подробности.
На рис. 3 в окне 1 представлена сеть понятий (активна третья кнопка в нижней строке этого окна). Если подвести к значку возле выбранного понятия указатель мыши и сделать двойной щелчок ее левой кнопкой, то раскроется список всех понятий, связанных с выбранным. Чтобы просмотреть всю информацию, относящуюся к данному понятию, следует щелкнуть мышью по первому пункту (<все>) раскрытого списка. После этого в окне 2 появятся все предложения текстов, включающие это понятие, причем оно будет выделено цветом. В том случае, когда пользователя интересует не вся информация о выбранном понятии, а лишь касающаяся его связи с одним из понятий в раскрытом ниже списке окна 1, следует указать мышью на это связанное с исходным понятие. Тогда в окне 2 появятся все предложения текстов, включающие выбранную описанным способом пару понятий, выделенную цветом. Если сделать двойной щелчок мышью по интересующему нас предложению в окне 2, то в окне 3 появится соответствующее место текста (на рис. 3 они выделены темным в этих двух окнах).
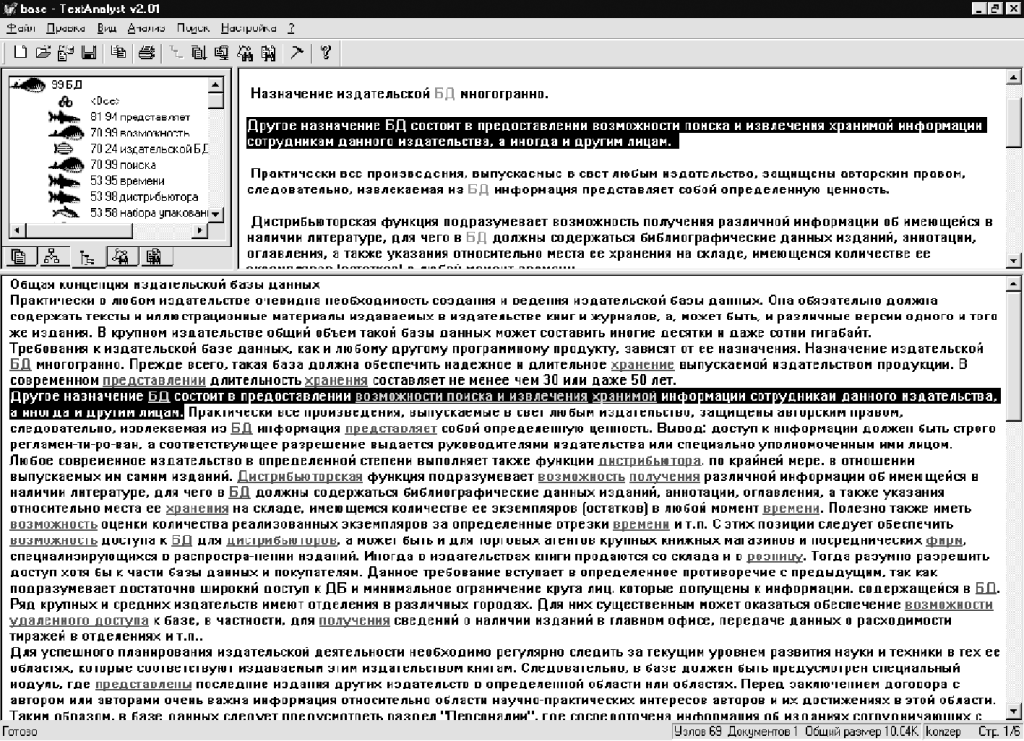
Теперь следует обратить внимание на пары чисел, расположенных вблизи понятий в окне 1 на рис. 3. Ближайшее к понятию число представляет его смысловой вес. Его значение изменяется от 1 до 100 и показывает, насколько важную роль играет это понятие для смысла всего текста, иначе говоря, ранжирует данное понятие. Максимальное значение, равное 100, говорит о том, что понятие является ключевым и представляет важнейшую тему текста. В нашем случае самым важным является понятие базы данных (БД), вследствие чего ему приписан вес 99. Малый смысловой вес, близкий к единице, показывает, что соответствующая тема лишь вскользь упомянута в тексте и количество информации, относящейся к данному понятию, минимально.
Другое число, находящееся ближе к раскрытому узлу, представляет вес связи понятия, расположенного в узле или вершине раскрытого списка, и данного понятия. Вес связей также принимает значение от 1 до 100. Большое значение веса связи от одного понятия к другому, близкое к 100, указывает на то, что подавляющая часть информации в тексте, касающаяся первого, касается в то же время и второго понятия — первая тема почти всегда излагается в контексте второй. Иначе говоря, два этих понятия тесно коррелированны друг с другом. При малых значениях, близких к единичному, узловое или первое понятие слабо связано со вторым, а уровень их взаимной корреляции близок к нулю. Следует отметить, что связь между парой понятий сети характеризуется направлением (т. е. подобна вектору). Связь от первого понятия ко второму не совпадает по величине с обратной связью, т. е. от второго к первому. Таким образом, сеть понятий действительно представляет идеальное описание текста — информация в ней отражает все присутствующие смысловые связи, т. е. обеспечивает полноту смыслового портрета анализируемого документа.
Тематическая структура
Для большинства из нас более привычны направленные графы информационного представления документов, в которых связи ориентированы в направлении от главного к второстепенному. Ему соответствует так называемая «тематическая структура» рассматриваемого документа. Она описывает содержание анализируемых текстов в виде иерархии связанных тем и подтем. Все темы и подтемы выражены в терминах исходного текста и соответствуют узлам сети понятий. Но в данном случае связи между понятиями односторонние и направлены от главного понятия к подчиненным.
Таким образом, тематической структуре соответствует иерархическое представление — от каждой темы раскрываются связи только к ее собственным подтемам, от них — к подтемам следующего уровня и т. д. Тематическая структура имеет вид дерева, в корне которого стоит главная тема, в ветвях — подтемы. Общий вид тематической структуры отражает смысловую организацию анализируемого документа. Если вся информация в документе подчинена единой теме, структура будет иметь вид дерева с единственным корнем. Если же его содержание отражает несколько тематических направлений, не связанных друг с другом, то дерево распадается на несколько независимых кустов, корни которых представляют главные темы, не связанные друг с другом.
Для просмотра тематической структуры следует активизировать в окне 1 закладку «Тематическая структура», нажав вторую кнопку слева в этом окне. На рис. 4 (интерфейс программы TextAnalyst 2.01 с загруженным текстовым документом и результатами анализа тематической структуры этого документа) тематическая структура представлена в окне 1 в виде дерева понятий — названий тем, некоторые из которых имеют раскрывающиеся списки связей с подтемами. Понятия в корне дерева представляют список главных тем текстов, а связанные с ними элементы в списках последующих уровней — списки подтем.
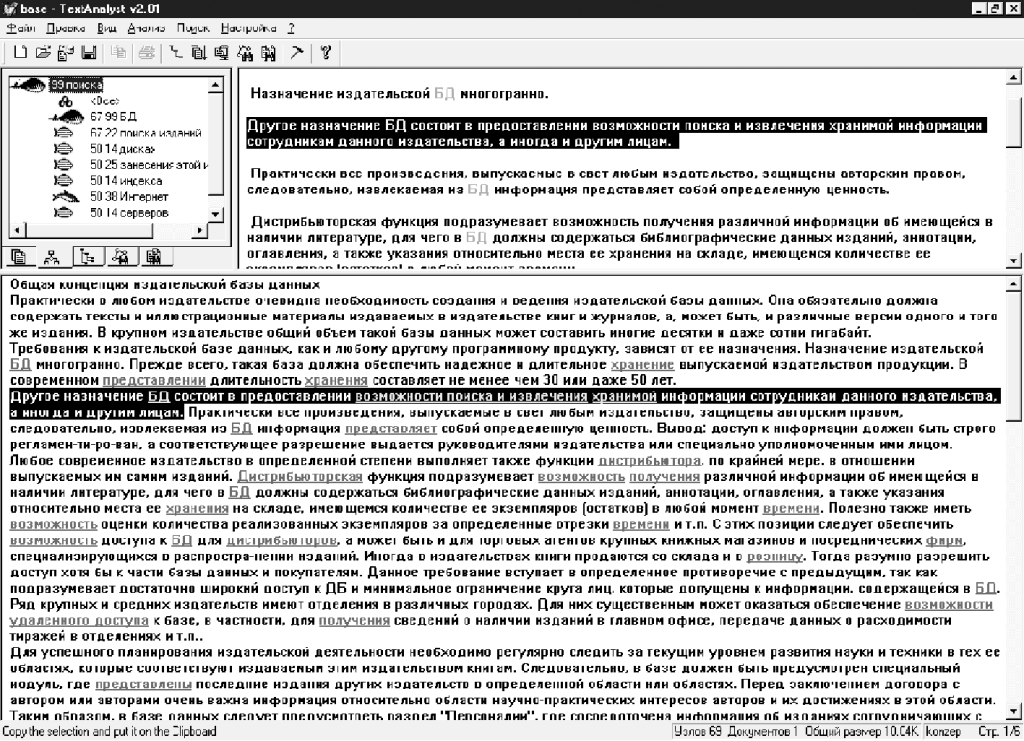
Программа TextAnalyst дает возможность регулировать степень связности тематического дерева. Для этого следует изменять порог по весу связей в сети понятий. Выбирая определенный уровень в качестве порогового значения связей, мы изменяем вид дерева, разбивая его на большее или меньшее количество тематических кустов. В результате появляется возможность взглянуть на структуру текста в различных срезах, на разных уровнях глубины материала. В плане интерфейса анализ тематической структуры документа аналогичен работе с семантической сетью. Анализ тематической структуры также иллюстрирует тот факт, что в программе осуществляется морфологический анализ слов с группированием однокоренных.
Таким образом, с помощью этой программы можно осуществить эффективную семантическую обработку текстов с извлечением ключевых слов и выражений. Допустим, что с помощью этой или другой программы мы обработали всю научную литературу, хранимую в библиотеке, и создали тематический каталог, в котором каждому документу сопоставлен набор ключевых слов и выражений. Как вести в нем тематический поиск?
Главное условие успешного поиска — включение в поисковое выражение требуемого набора ключевых слов, такого, который представлял бы собой адекватное отображение тематики, подлежащей поиску. Обычно рекомендуется извлекать такие выражения из тех работ, которые в полной степени удовлетворяют поставленной задаче. Например, вы случайно столкнулись с интересной работой (или несколькими близкими по тематике работами) и хотите отыскать другие публикации данного направления. Для достижения поставленной цели надо выделить из этой работы (или этих работ) набор термов, в наибольшей степени отражающий ее смысл, т. е. наиболее значимые слова и выражения. Составив из них поисковое выражение, вы гарантируете себе качественный поиск в тематическом каталоге любой библиотеки.
Эффективность поиска нужных документов в библиотеке можно описать двумя количественными характеристиками — это точность и охват. Точность µ определяется отношением числа релевантных (пригодных) документов R к общему количеству документов N, выбранных на основе поиска в тематическом каталоге (µ=R/N). Охват S характеризуется отношением числа релевантных документов в выборке R к общему числу релевантных документов T, описанных в тематическом каталоге и имеющихся в библиотеке (S=R/T).
В случае идеального поиска все выбранные документы полностью пригодны и исчерпывают список пригодных документов в базе данных, то есть е=1 и µ=1. Однако многочисленные исследования, выполненные различными специалистами, показали, что точность и охват связаны друг с другом обратной зависимостью, а максимальное значение суммы µ+S близко к 1,4.
Такой результат выглядит вполне осмысленным. Действительно, если мы хотим увеличить точность µ, то должны как можно более полно сформулировать запрос, включив в него большое количество различных термов, связанных с помощью операторов чтобы исключить возможность попадания в результаты поиска непригодных документов. Однако, в этом случае общее количество выбранных изданий не может быть большим, точнее — оно будет малым. Естественно, что не все релевантные документы, содержащиеся в базе данных, попадут в число выбранных.
Наоборот, если мы хотим увеличить охват, т. е. постараться выбрать наибольшее количество релевантных изданий из общего их числа в базе, следует сформулировать запрос как можно шире. Но в этом случае в выборку неизбежно попадет значительное число непригодных изданий, т. е. точность окажется сравнительно малой величиной.
В последнем случае увеличение количества выбранных изданий неизбежно увеличит время обработки результатов поиска. Реально, если количество выбранных изданий составляет сотни значений, то время оценки их пригодности становится чрезмерно большим, в результате пользователь утомляется, внимание его рассеивается, что неизбежно приводит к неточностям и ошибкам.
Владимир Абрамович Вуль, доцент Северо-Западного института печати, руководитель лаборатории «Электронных изданий», кандидат технических наук